
Multiple linear regression
This learning resource summarises the main teaching points about multiple linear regression (MLR), including key concepts, principles, assumptions, and how to conduct and interpret MLR analyses. Prerequisites:
|
What is MLR?
[edit | edit source]- Multiple linear regression (MLR) is a multivariate statistical technique for examining the linear correlations between two or more independent variables (IVs) and a single dependent variable (DV).
- Research questions suitable for MLR can be of the form "To what extent do X1, X2, and X3 (IVs) predict Y (DV)?"
e.g., "To what extent does people's age and gender (IVs) predict their levels of blood cholesterol (DV)?" - MLR analyses can be visualised as path diagrams and/or venn diagrams
-
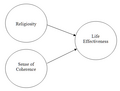 MLR studies the relation between two or more IVs and a single DV.
MLR studies the relation between two or more IVs and a single DV. -

-
 What other ways can you think of to explain the purpose of MLR?
What other ways can you think of to explain the purpose of MLR?
.png)


| View the accompanying screencast: [1] |
- DV: A normally distributed interval or ratio variable
- IVs: Two or more normally distributed interval or ratio variables or dichotomous variables. Note that it may be necessary to recode non-normal interval or ratio IVs or multichotomous categorical or ordinal IVs into dichotomous variables or a series of dummy variables).
Sample size
[edit | edit source]Enough data is needed to provide reliable estimates of the correlations. As the number of IVs increases, more inferential tests are being conducted, therefore more data is needed, otherwise the estimates of the regression line are probably unstable and are unlikely to replicate if the study is repeated.
Some rules of thumb:
- Use at least 50 cases plus at least 10 to 20 as many cases as there are IVs.
- Green (1991) and Tabachnick and Fidell (2007):
- 50 + 8(k) for testing an overall regression model and
- 104 + k when testing individual predictors (where k is the number of IVs)
- Based on detecting a medium effect size (β >= .20), with critical α <= .05, with power of 80%.
To be more accurate, study-specific power and sample size calculations should be conducted (e.g., use A-priori sample Size calculator for multiple regression; note that this calculator uses f2 for the anticipated effect size - see the Formulas link for how to convert R2 to to f2).
Normality
[edit | edit source]- Check the univariate descriptive statistics (M, SD, skewness and kurtosis). As a general guide, skewness and kurtosis should be between -1 and +1.
- Check the histograms with a normal curve imposed.
- Note: Be wary (i.e., avoid!) using inferential tests of normality (e.g., the Shapiro–Wilk test - they are notoriously overly sensitive for the purposes/needs of regression).
- Normally distributed variables will enhance the MLR solution. Estimates of correlations will be more reliable and stable when the variables are normally distributed, but regression will be reasonably robust to minor to moderate deviations from non-normal data when moderate to large sample sizes are involved. Also examine scatterplots for bivariate outliers because non-normal univariate data may make bivariate and multivariate outliers more likely.
- Further information:
- Does your data violate linear regression assumptions? (quality-control-plan.com)
- Regression when the OLS residuals are not normally distributed (StackExchange)
- How do I perform a regression on non-normal data which remain non-normal when transformed? (StackExchange)
Linearity
[edit | edit source]Check scatterplots between the DV (Y) and each of the IVs (Xs) to determine linearity:
- Are there any bivariate outliers? If so, consider removing the outliers.
- Are there any non-linear relationships? If so, consider using a more appropriate type of regression.
Homoscedasticity
[edit | edit source]Based on the scatterplots between the IVs and the DV:
- Are the bivariate distributions reasonably evenly spread about the line of best fit?
- Also can be checked via the normality of the residuals.
Multicollinearity
[edit | edit source]IVs should not be overly correlated with one another. Ways to check:
- Steps are shown in this screencast: [2]
- Examine bivariate correlations and scatterplots between each of the IVs (i.e., are the predictors overly correlated - above ~.7?).
- Check the collinearity statistics in the coefficients table:
- Various recommendations for acceptable levels of VIF and Tolerance have been published.
- Variance Inflation Factor (VIF) should be low (< 3 to 10) or
- Tolerance should be high (> .1 to .3)
- Note that VIF and Tolerance have a reciprocal relationship (i.e., TOL=1/VIF), so only one of the indicators needs to be used.
- For more information, see [3]
Check whether there are influential MVOs using Mahalanobis' Distance (MD) and/or Cook’s D (CD):
- Steps are shown in these screencasts: [4][5][6]
- SPSS: Linear Regression - Save - Mahalanobis (can also include Cook's D)
- After execution, new variables called mah_1 (and coo_1) will be added to the data file.
- In the output, check the Residuals Statistics table for the maximum MD and CD.
- The maximum MD should not exceed the critical chi-square value with degrees of freedom (df) equal to number of predictors, with critical alpha =.001. CD should not be greater than 1.
- If outliers are detected:
- Go to the data file, sort the data in descending order by mah_1, identify the cases with mah_1 distances above the critical value, and consider why these cases have been flagged (these cases will each have an unusual combination of responses for the variables in the analysis, so check their responses).
- Remove these cases and re-run the MLR.
- If the results are very similar (e.g., similar R2 and coefficients for each of the predictors), then it is best to use the original results (i.e., including the multivariate outliers).
- If the results are different when the MVOs are not included, then these cases probably have had undue influence and it is best to report the results without these cases.
Normality of residuals
[edit | edit source]The residuals should be normally distributed around 0.
- Residuals are more likely to be normally distributed if each of the variables normally distributed, so check normality first.
- There are three ways of visualising residuals. In SPSS - Analyze - Regression - Linear - Plots:
- Scatterplot: ZPRED on the X-axis and ZRESID on the Y-axis
- Histogram: Check on
- Normal probability plot: Check on
- Scatterplot should have no pattern (i.e. be a "blob").
- Histogram should be normally distributed
- Normal probability plot should fall along the diagonal line
- If residuals are not normally distributed, there is probably something wrong with the distribution of one or more variables - re-check
Types
[edit | edit source]There are several types of MLR, including:
| Type | Characteristics |
|---|---|
| Direct (or Standard) |
|
| Hierarchical |
|
| Forward |
|
| Backward |
|
| Stepwise |
|
Forward, Backward, and stepwise regression hands the decision-making power over to the computer which should be discouraged for theory-based research.
For more information, see Multiple linear regression I (Lecture)
Results
[edit | edit source]- MLR analyses produce several diagnostic and outcome statistics which are summarised below and are important to understand.
- Make sure that you can learn how to find and interpret these statistics from statistical software output.
Correlations
[edit | edit source]Examine the linear correlations between (usually as a correlation matrix, but also view the scatterplots):
- IVs
- each IV and the DV
- DVs (if there is more than 1)
Effect sizes
[edit | edit source]R
[edit | edit source]- (Big) R is the multiple correlation coefficient for the relationship between the predictor and outcome variables.
- Interpretation is similar to that for little r (the linear correlation between two variables), however R can only range from 0 to 1, with 0 indicating no relationship and 1 a perfect relationship. Large values of R indicate more variance explained in the DV.
- R can be squared and interpreted as for r2, with a rough rule of thumb being .1 (small), .3 (medium), and .5 (large). These R2 values would indicate 10%, 30%, and 50% of the variance in the DV explained respectively.
- When generalising findings to the population, the R2 for a sample tends to overestimate the R2 of the population. Thus, adjusted R2 is recommended when generalising from a sample, and this value will be adjusted downward based on the sample size; the smaller the sample size, the greater the reduction.
- The statistical significance of R can be examined using an F test and its corresponding p level.
- Reporting example: R2 = .32, F(6, 217) = 19.50, p = .001
- "6, 217" refers to the degrees of freedom - for more information, see about half-down this page
Cohen's ƒ2
[edit | edit source]- Cohen's ƒ2 is based on the R2 and is an alternate indicator of effect size for MLR.
Coefficients
[edit | edit source]An MLR analysis produces several useful statistics about each of the predictors. These regression coefficients are usually presented in a Results table (example) which may include:
- Constant (or Intercept) - the starting value for DV when the IVs are 0
- B (unstandardised) - used for building a prediction equation
- Confidence intervals for B - the probable range of population values for the Bs
- β (standardised) - the direction and relative strength of the predictors on a scale ranging from -1 to 1
- Zero-order correlation (r) - the correlation between a predictor and the outcome variable
- Partial correlations (pr) - the unique correlations between each IV and the DV (i.e., without the influence of other IVs) (labelled "partial" in SPSS output)
- Semi-partial correlations (sr) - similar to partial correlations (labelled "part" in SPSS output); squaring this value provides the percentage of variance in the DV uniquely explained by each IV (sr2)
- t, p - indicates the statistical significance of each predictor. Degrees of freedom for t is n - p - 1.
Equation
[edit | edit source]- A prediction equation can be derived from the regression coefficients in a MLR analysis.
- The equation is of the form
(for predicted values) or
(for observed values)


Residuals
[edit | edit source]A residual is the difference between the actual value of a DV and its predicted value. Each case will have a residual for each MLR analysis. Three key assumptions can be tested using plots of residuals:
- Linearity: IVs are linearly related to DV
- Normality of residuals
- Equal variances (Homoscedasticity)
Power
[edit | edit source]- Post-hoc statistical power calculator for MLR (danielsoper.com)
Advanced concepts
[edit | edit source]- Partial correlations
- Use of hierarchical regression to partial out or remove the effect of 'control' variables
- Interactions between IVs
- Moderation and mediation
Writing up
[edit | edit source]When writing up the results of an MLR, consider describing:
- Assumptions: How were they tested? To what extent were the assumptions met?
- Correlations: What are they? Consider correlations between the IVs and the DV separately to the correlations between the IVs.
- Regression coefficients: Report a table and interpret
- Causality: Be aware of the limitations of the analysis - it may be consistent with a causal relationship, but it is unlikely to prove causality
- See also: Sample write-ups
FAQ
[edit | edit source]What if there are univariate outliers?
[edit | edit source]Basically, explore and consider what the implications might be - do these "outliers" impact on the assumptions? A lot depends on how "outliers" are defined. It is probably better to consider distributions in terms of the shape of the histogram and skewness and kurtosis, and whether these values are unduely impacting on the estimates of linear relations between variables. In other words, what are the implications? Ultimately, the researcher needs to decide whether the outliers are so severe that they are unduely influencing results of analyses or whether they are relatively benign. If unsure, explore, test, try the analyses with and without these values etc. If still unsure, be conservative and remove the data points or recode the data.
See also
[edit | edit source]| Search for Multiple linear regression on Wikipedia. |
- Tutorials/Activities
- Lectures
- Other
- Four assumptions of multiple regression that researchers should always test (Osborne & Waters, 2002)
- Least-Squares Fitting
- Logistic regression
- Multiple linear regression (Commons)
References
[edit | edit source]- Allen & Bennett 13.3.2.1 Assumptions (pp. 178-179)
- Francis 5.1.4 Practical Issues and Assumptions (pp. 126-128)
- Green, S. B. (1991). How many subjects does it take to do a regression analysis?. Multivariate Behavioral Research, 26, 499-510.
- Knofczynski, G. T., & Mundfrom, D. (2008). Sample sizes when using multiple linear regression for prediction. Educational and Psychological Measurement, 68, 431-442.
- Wilson Van Voorhis, C. R. & Morgan, B. L. (2007). Understanding power and rules of thumb for determining sample sizes. Tutorials in Quantitative Methods for Psychology, 3(2), 43-50.
External links
[edit | edit source]- Correlation and simple least squares regression (Zady, 2000)
- Multiple regression (Statsoft)
- Multiple regression assumptions (ERIC Digest)