
Web Development with Webmachine for Erlang
Webmachine – The Framework
[edit | edit source]Origin and Aims
[edit | edit source]Webmachine is a REST framework built on top of Mochiweb[1], a web server written in Erlang. It aims at easily building a web service with correct HTTP semantics while not having to deal with HTTP in the business logic. Webmachine was refactored out of Riak as explained in the talk "Webmachine: a Practical Executable Model of HTTP"[2] by one of its creators, Justin Sheehy. Since it was the initial implementation, this article mostly discusses the Erlang one and is focused on writing a REST service with Webmachine for Erlang.
Principles
[edit | edit source]The framework implements some default behaviour and the application has to implement a given set of functions which will be called by Webmachine (Hollywood Principle). All functions have the same signature which is:
f(ReqData Context) -> {Result, ReqData, Context}.
- Result
- contains mostly true/false which act as signals for the decision core in the framework code.
- ReqData
- stores the request and response. Every function can read and modify those and pass them on to the next function.
- Context
- is ignored by the framework. In this parameter the application can store internal state for processing of one request.
Webmachine enforces a side effect free programming model because of the underlying implementation in Erlang. The only possibility to modify state inside another function is to pass an argument to it. With this in mind, a Webmachine application can be seen as a set of functions which call each other with their computed values.
Structure of a Webmachine Application
[edit | edit source]An application consists of one ore more resources. These are Erlang modules which usually implement framework callbacks and internal functions. The resources are located in the /src folder. For every application there is also a dispatch.conf file which configures the routes of an URL accessing request to a resource.
Building a REST Service
[edit | edit source]The running example will be a paper repository. It provides an API to store, change, retrieve and delete papers with their title and author.
The operations which are implemented in the example are the following:
| HTTP Method | Route | Content Type | Request Body | Status Code | Response |
| GET | /paper/id | application/json | 200 | {"id":"123", "title":"Introduction to Webmachine"} | |
| GET | /paper/id | text/html | 200 | <html><body>id</body></html> | |
| PUT | /paper/id | application/json | {"id":"123", "title":"Introduction to Webmachine"} | 201 (if created), 200 (if updated) | {"id":"123", "title":"Introduction to Webmachine"} |
| POST | /paper | application/json | {"id":"123", "title":"Introduction to Webmachine"} | 201 | {"id":"123", "title":"Introduction to Webmachine"} |
| DELETE | /paper/id | 204 |
The example will be developed in a test driven manner. The API tests are written with the excellent Python library Requests[3] by Kenneth Reitz. Erlang unit tests are written with EUnit[4].
All source code can be found in a Github repository[5].
Start a Webmachine Application
[edit | edit source]What we expect from the fresh Application
[edit | edit source]A barebones Webmachine application listens to port 8888 and returns a short html response stating "Hello world".
# -*- coding: utf-8 -*-
#!/usr/bin/python
import requests
import unittest
class TestPaperAPI(unittest.TestCase):
def setUp(self):
self.base_url = "http://localhost:8888"
def test_get_on_root_returns_html_hello_world(self):
resp = requests.get(self.base_url)
self.assertEqual(resp.content, "<html><body>Hello, new world</body></html>")
if __name__ == "__main__":
suite = unittest.TestLoader(verbosity=2).loadTestsFromTestCase(TestPaperAPI)
unittest.TextTestRunner.run(suite)
Running the test with
python -m unittest api_tests.py -v
should produce a failing assertion. If this test succeeds, it means that there is already an application running on that port.
Install and run a basic Webmachine Application
[edit | edit source]For this tutorial a working installation of Erlang is needed. There are precompiled binaries available[6] [7] and it is also accesible via package managers.
After this, clone the Webmachine code repository[8] from github.
git clone git://github.com/basho/webmachine.git
Then let it generate the skeleton code for our application which we will call prp – a short hand for paper repository and the namespace used for this tutorial code.
webmachine/scripts/new_webmachine.sh prp
After generating the code we build and run it:
make ./start.sh
Note: Everytime the code is built, the changed modules are reloaded into the Erlang VM with hot code reloading. Because a full run of make checks all dependencies with rebar and is therefore comparatively slow. To speed up develpment it is recommended to run
rebar compile
if no new dependencies were added and just the written Webmachine application needs to be compile.
Now the test should pass.
Adding the testrunner to the Makefile
[edit | edit source]For convenience it is recommended to add the api_tests.py to a new test directory at the application root. mkdir test The directory structure should look like:
tree -L 1 . ├── Makefile ├── deps ├── ebin ├── include ├── priv ├── rebar ├── rebar.config ├── src ├── start.sh └── test
In addition the testrunner is added to the Makefile as a new target:
api-tests:
$(shell python -m unittest discover test '*_tests.py' -v)
Now type
make api-tests
to execute the test suite.
Configure Routes
[edit | edit source]For every request a Webmachine application decides which function in which module it has to call. This configuration is done in a file in priv/dispatch.conf. The syntax for this configuration can be found at the documentation[9].
In priv/dispatch.conf:
{["paper", id], prp_paper, []}.
% The canonical resource for everything else
{[], prp_resource, []}.
The first line tells Webmachine to look into the resource file prp_paper.erl to generate a response for a request to /paper/id. In addition, for a URL path /paper/foobar the part after the second slash, in this case "foobar" is accessible via the atom 'id'. With this help we can later get the id of a paper via:
wrq:path_info(id).
Adding a storage layer
[edit | edit source]The service which is built in this tutorial requires a storage. A simple abstraction layer exists around it whose creation is not discussed in this tutorial. It uses an in-memory Mnesia database, a distributed database written in Erlang which is part of the Erlang distribution as well so there is no need to install drivers and databases.
Please get the source code from the Github repository [5]. The relevant files are in src/prp_schema.erl and priv/prp_datatypes.hrl. The corresponding unit tests are located in test/prp_schema_tests.erl.
GET /paper/id
[edit | edit source]Writing a first test
[edit | edit source]At first a test method is added to the TestPaperAPI class:
def test_get_on_paper_returns_id_in_html(self):
for id in 1,2,3:
resp = requests.get(self.paper_url + str(id))
self.assertEqual(resp.status_code, 200)
self.assertEqual(resp.content, "<html><body>" + str(id) + "</body></html>")
Running the test via
make api_tests
should fail.
Implementing a GET response in HTML
[edit | edit source]As configured in dispatch.conf the request gets routed to src/prp_paper.erl. On application startup the init/1 method is called. It fills the in-memory Mnesia database wich is used for testing with inital data to test with (Fixtures).
-module(prp_paper).
-compile([export_all]).
-include_lib("webmachine/include/webmachine.hrl").
init(Config) ->
%% fill the database with some test data
prp_schema:init_tables(),
prp_schema:fill_with_dummies(),
content_types_provided(RD, Ctx) ->
{[ {"text/html", to_html} ], RD, Ctx}.
allowed_methods(RD, Ctx) ->
{['GET', 'HEAD'], RD, Ctx}.
to_html(RD, Ctx) ->
Id = wrq:path_info(id, RD),
Resp = "<html><body>" ++ Id ++ "</body></html>",
{Resp, RD, Ctx}.
The function content_types_provided/2 dispatches the request to that module to a function – in this case to_html/2. Erlang functions are referenced using the function_name/arity notation. to_html/2 means the function to_html with two arguments.
Turn on tracing for Debugging
[edit | edit source]
Webmachine has a simple but effective way to debug an application. It is possible to trace the decisions made in the Webmachine core to get an idea where things go wrong. Let's go back to src/prp_paper.erl and turn on tracing. The init/1 function should now be:
src/prp_paper.erl
init(Config) ->
%% fill the database with some test data
prp_schema:init_tables(),
prp_schema:fill_with_dummies(),
%% enable tracing the decision core for debugging
{{trace, "traces"}, Config}.
It is also necessary to add a new dispatch target to look at the traces via a web browser because Webmachine renders the decision flow into an HTML Canvas.
Add to dispatch.conf:
{["dev", "wmtrace", '*'], wmtrace_resource, [{trace_dir, "traces"}]}.
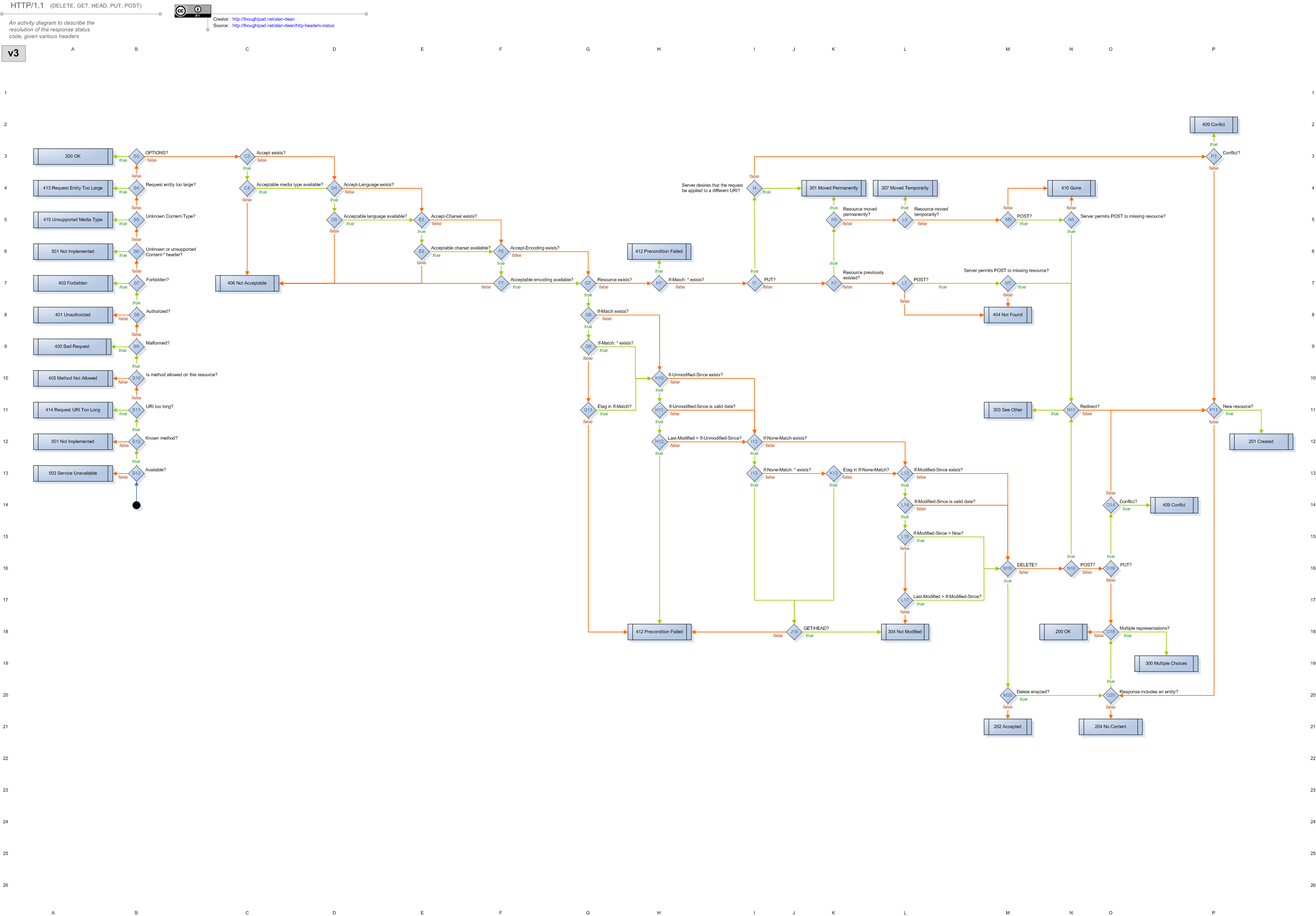
Now it is possibility to look at a trace after another run of the testsuite. It should look like the example trace in figure 1.
Making sure that not existing papers return a 404
[edit | edit source]If an entity doesn't exist it is necessary to return the status code 404 Not Found.
def test_get_on_nonexisting_paper_returns_404(self):
resp = requests.get(self.paper_url + '1235')
self.assertEqual(resp.status_code, 404)
Running that test shows us that by default, Webmachine states that each resource is available. To change that behaviour we implement resource_exists/2 and return true/false if a paper exists.
src/prp_paper.erl
resource_exists(RD, Ctx) ->
Id = wrq:path_info(id, RD),
{prp_schema:paper_exists(Id), RD, Ctx}.
Now, the test should pass.
Responding in different formats
[edit | edit source]In Webmachine it is possible to respond in different formats depending on the format desired by the client. The negotiation takes place in Mochiweb.
Requesting JSON
[edit | edit source]In addition to the already described response in HTML format a JSON response is implemented. A test describes the wanted behaviour.
def test_get_on_paper_returns_id_in_json(self):
for id in 1,2,3:
resp = requests.get(self.paper_url + str(id), headers=self.json_headers)
self.assertEqual(resp.status_code, 200)
self.assertEqual(resp.content, '{"id":' + '"' + str(id) + '",'\
'"title":'+ '"' + str(id) + '"}')
As I am using an outdated version of the requests library the response is not parsed as JSON but interpreted as a string, which is not the way one should to it. In a current version of requests it is possible to use response.json to get the parsed JSON and compare it to a Python dictionary.
Implement a JSON Response for GET /paper/id
[edit | edit source]At first register a JSON producing function (in this case to_json/2) for a client requesting this format. It is specified in content_types_provided/2.
src/prp_resource.erl
content_types_provided(RD, Ctx) ->
{[ {"text/html", to_html}, {"application/json", to_json} ], RD, Ctx}.
If a client wishes another format than html or json it would get the proper HTML status code 415 Unsupported Media Type. To encode the paper data as JSON the mochijson library is used.
to_json(RD, Ctx) ->
Id = wrq:path_info(id, RD),
{paper, Id2, Title} = prp_schema:read_paper(Id),
Resp = mochijson:encode({struct, [
{id, integer_to_list(Id2)},
{title, Title}
]}),
{Resp, RD, Ctx}.
Now all tests should pass.
PUT /paper/id
[edit | edit source]A PUT to /paper/id should add or modify a Paper with the given id
[edit | edit source]With PUT one can add a certain entity to a well-known location or modify it. This request should be idempotent which means that each identical request has the same effect as the first one. It is also important to note that an existing entity will be modified. If it is not possible than the response should be 409 Conflict. To make the application watch for conflicts is_conflict/2 must be implemented. In this example no conflict can occur. Every client is allowed to make any modification and the typical use case of non matching version numbers[10] does not apply.
The wished behaviour is descibed in the following tests: A PUT should create a
resource and update an existing one.
class TestPaperAPI(unittest.TestCase):
def setUp(self):
self.base_url = "http://localhost:8888"
self.paper_url = "http://localhost:8888/paper/"
self.json_headers ={"Content-Type" : "application/json", "Accept" : "application/json"}
self.new_paper = {"title": "ABC"}
self.new_paper2 = {"title": "DEF"}
def test_put_new_paper(self):
url = self.paper_url + '0'
resp = requests.put(url, data=self.new_paper, headers=self.json_headers)
self.assertEqual(resp.status_code, 200)
self.assertEqual(resp.content, '{"id":"0","title":"ABC"}')
# Test durability
resp2 = requests.get(url)
def test_put_updates_paper(self):
url = self.paper_url + '0'
resp = requests.get(url)
# Paper exists
self.assertEqual(resp.status_code, 200)
resp2 = requests.put(url, data=self.new_paper2, headers=self.json_headers)
self.assertEqual(resp2.status_code, 200)
self.assertEqual(resp2.content, '{"id":"0", "title":"DEF"}')
Running this test produces an assertion error because the application does not allow a PUT to this resource. To fix this it is necessary to modify allowed_methods/2 in src/prp_paper.erl.
allowed_methods(RD, Ctx) ->
{['GET', 'PUT', 'HEAD'], RD, Ctx}.
In addition a handler for the PUT request has to be registered in content_types_accepted/2 in src/prp_paper.erl:
content_types_accepted(RD, Ctx) ->
{ [ {"application/json", from_json} ], RD, Ctx }.
from_json(RD, Ctx) ->
Id = wrq:path_info(id, RD),
<<"title=", Title/binary>> = wrq:req_body(RD),
Title1 = binary_to_list(Title),
prp_schema:create_paper(list_to_integer(Id), Title1),
JSON = list_to_binary(paper2json(Id, Title)),
Resp = wrq:set_resp_body(JSON, RD),
{true, Resp, Ctx}.
-spec paper2json(string(), string()) -> string().
paper2json(Id, Title) ->
mochijson:encode({struct, [
{id, Id},
{title, Title} ]}).
The explicit adding of JSON to the response body produces a 200 OK with the freshly created entity. If you prefer a 204 No Content just return RD instead of Resp.
The helper function paper2json/2 can also be used in to_json/2 follow the Don't Repeat Yourself principle. The function should be refactored to:
to_json(RD, Ctx) ->
Id = wrq:path_info(id, RD),
{paper, Id2, Title} = prp_schema:read_paper(Id),
Resp = paper2json(integer_to_list(Id2), Title)
{Resp, RD, Ctx}.
After another
make api-tests
all tests should be fulfilled.
A Note on Types
[edit | edit source]In this tutorial type specifications are used for custom helper functions. It is not necessary in Erlang and is just added to make the examples more clear. The notation reads as the following:
-spec function_name(argument_type())-> return_type().
In a later section the type wm_reqdata() is used which represents a request and its response. As Webmachine currently does not include full type specifications it is necessary to add a type declaration to deps/webmachine/wm_reqdata.hrl.
-opaque wm_reqdata() :: wm_reqdata.
Or as a quick fix this declaration can be added into src/prp_paper.erl:
-type wm_reqdata() :: wm_reqdata.
Respond with 201 Created instead of 200 OK
[edit | edit source]If the response should have no content but only a signal that the resource was created (status code 201 Created) it is necessary to explicitly add this information to the response. In src/prp_paper.erl modify from_json/2 to the following:
from_json(RD, Ctx) ->
Id = wrq:path_info(id, RD),
<<"title=", Title/binary>> = wrq:req_body(RD),
prp_schema:create_paper(list_to_integer(Id), binary_to_list(Title)),
%% Enable Response Code 201 at decision node P11 in diagram
R = wrq:set_resp_header("Location", Id, RD),
{true, R, Ctx}.
DELETE /paper/id
[edit | edit source]DELETE /paper/id should delete the record
[edit | edit source]A test for a permanent deletion of a paper with a given id could look like the following one. First, a paper is created, than deleted and than it should be not found by the application.
def test_delete_paper(self):
# create it first
url = self.paper_url + '0'
resp = requests.put(url, data=self.new_paper, headers=self.json_headers)
self.assertEqual(resp.status_code, 200)
resp1 = requests.delete(url)
self.assertEqual(resp1.status_code, 204)
# test if durable
resp2 = requests.get(url)
self.assertEqual(resp2.status_code, 404)
This test should fail bacause the status code of resp1 is 405 Method Not Allowed.
Implementing a DELETE
[edit | edit source]To make a DELETE succesful is required to first allow this HTTP method for a resource, in this case in src/prp_paper.erl.
allowed_methods(RD, Ctx) ->
{['GET', 'PUT', '', 'HEAD'], RD, }.
After this a
make api-tests
fails with a status code 500 Internal Server Error because a DELETE is allowed but the Webmachine callback delete_resource/2 is not exported from the module. To fulfill Webmachine's expectation the function could be implemented like this the following:
delete_resource(RD, Ctx) ->
Id = wrq:path_info(id, RD),
case prp_schema:delete_paper(Id) of
ok -> {true, RD, Ctx};
_Else -> {false, RD, Ctx}
end.
The returned status (first entry in returned triple) marks if the delete was successful. If it was not, the application returns the status code 500 Internal Server Error.
POST /paper
[edit | edit source]POST to /paper adds a new Paper
[edit | edit source]While PUT is fine to add a paper with an id specified by the client it does not allow clients to just add a paper without knowledge about its URI. For this a POST is used because accoring to this table of RESTful HTTP methods a POST to a collection (in this case /paper) adds a new entity to it.
Like for the other methods a test is used to specify the wanted behaviour.
def test_post_new_paper(self):
resp = requests.post(self.paper_url, data=self.new_paper,
headers=self.json_headers)
self.assertEqual(resp.status_code, 201)
self.assertNotEqual(resp.content, '')
Because it is not known in the test which id the created paper has, we just assert that the content is not empty. With proper JSON parsing it would be much easier.
Adding a route to /paper
[edit | edit source]To /priv/dispatch.conf we add a route to allow a request to /paper:
{["paper"], prp_paper, []}.
It is absolutely necessary to put that behind the first rule because the rules are matched from top to bottom which will result in a no-set id from the request path. The whole file should be like:
{["paper", id], prp_paper, []}.
{["paper"], prp_paper, []}.
{["dev", "wmtrace", '*'], wmtrace_resource, [{trace_dir, "traces"}]}.
% The canonical resource for everything else
{[], prp_resource, []}.
Implementing a POST which creates a Resource
[edit | edit source]Webmachine treats a POST to an URI like a PUT to this location if it is specified that a POST creates a resource. Therefore the function post_is_create/2 has to be implemented in src/prp_paper.erl and has to return true. In addition create_path/2 has to be written which produces the path onto which the POST is treated like a PUT. Please note that because post_is_create/2 returns true the response code automatically is set to 201 Created and the location header is set.
post_is_create(RD, Ctx) ->
{true, RD, Ctx}.
create_path(RD, Ctx) ->
Path = integer_to_list(generate_id()),
{Path, RD, Ctx}.
-spec generate_id()->integer().
generate_id() ->
mnesia:table_info(paper, size) + 1.
Unfortunately Webmachine does not rematch the dispatch rules on the created path which means that the created id is not accessible via wrq:path_info(id, RD) because this funciton still works with a normal PUT but returns undefined if the request is a POST. This means we have to modify the handling from_json/2 in src/prp_paper.erl.
from_json(RD, Ctx) ->
Id = id_from_path(RD),
<<"title=", Title/binary>> = wrq:req_body(RD),
Title1 = binary_to_list(Title),
prp_schema:create_paper(list_to_integer(Id), Title1),
JSON = paper2json(Id, Title1),
Resp = wrq:set_resp_body(JSON, RD),
{true, Resp, Ctx}.
create_path(RD, Ctx) ->
Path = "/paper/" ++ integer_to_list(generate_id()),
{Path, RD, Ctx}.
-spec id_from_path(wm_reqdata()) -> string().
id_from_path(RD) ->
case wrq:path_info(id, RD) of
undefined->
["paper", Id] = string:tokens(wrq:disp_path(RD), "/"),
Id;
Id -> Id
end.
A run of the test shows that this implementation was not sufficient. The test of the PUT still runs but POST fails with a 404 Not Found instead of a 200 OK. The reason is that per default a POST to a non existing resource is forbidden.

This problem is solved by implementing allow_missing_post/2 in src/prp_paper.erl.
allow_missing_post(RD, Ctx) ->
{true, RD, Ctx}.
Now all tests should pass.
Making sure that POST/PUT are well formed
[edit | edit source]Webmachine has a framework function malformed_request/2 which is called too erly (decision node B9 in the diagram[11]) to put in any application logic.
Any match out of data given by the API user might lead to a badmatch exception whch should be avoided because the crashing module will only be restarted if the number of crashes in a given interval are less that what is specified in its supervisor. With Webmachine the default is 10 times in 10 seconds (see line 57 in prp_sup.erl). Therefore one should check user input in production.
As an example it is shown how to check if data is provided to save.
def test_put_without_data_is_malformed(self):
url = self.paper_url + '1'
resp = requests.put(url, data = {}, headers=self.json_headers)
self.assertEqual(resp.status_code, 400)
The test should fail.
An implementation of how to check if a title is provided (remember, the paper consist of an id and a title) could look like the following code listing:
from_json(RD, Ctx) ->
from_json(RD, Ctx, get_title(RD)).
-spec from_json(wm_reqdata(), any(), {error, no_data})
-> {{halt, 400}, wm_reqdata(), any()};
(wm_reqdata(), any(), string())
-> {true, wm_reqdata(), any()}.
from_json(RD, Ctx, {error, no_data}) ->
%% There is nothing to post, it's malfomed
{{halt, 400}, RD, Ctx};
from_json(RD, Ctx, Title) ->
Id = id_from_path(RD),
case resource_exists(RD, Ctx) of
{false, _, _} ->
Resp = wrq:set_resp_header("Location", Id, RD);
{true, _, _} -> Resp = RD
end,
prp_schema:create_paper(list_to_integer(Id), Title),
JSON = paper2json(Id, Title),
R = wrq:set_resp_body(JSON, Resp),
{true, R, Ctx}.
-spec get_title(wm_reqdata()) -> string() | {atom(), atom()}.
get_title(RD) ->
case wrq:req_body(RD) of
<<"title=", Title/binary>> ->
binary_to_list(Title);
_Else ->
{error, no_data}
end.
Now all test should pass again.
Are POST and PUT equal now?
[edit | edit source]It is also worth noting that because the recently implemented POST behaves like a PUT to the path created by create_path/2. But with one major difference: On a POST, create_path/2 is always called which means that a POST to /paper/id will be applied to /paper/generated_id. A test confirms this hypothesis.
def test_post_specific_paper_creates_another(self):
url = self.paper_url + '1'
resp = requests.post(url, data=self.new_paper, headers=self.json_headers)
self.assertEqual(resp.status_code, 201)
self.assertEqual(resp.content, '{"id":"1","title":"ABC"}')
# new one was created
self.assertNotEqual(resp.headers["location"], None)
# the new one is not the one which the POST was applied to
self.assertNotEqual(resp.headers["location"], self.paper_url+'1')
Full Source Code Listing
[edit | edit source]test/api_tests.py
# -*- coding: utf-8 -*-
#!/usr/bin/python
import requests
import unittest
class TestPaperAPI(unittest.TestCase):
def setUp(self):
self.base_url = "http://localhost:8888"
self.paper_url = "http://localhost:8888/paper/"
self.json_headers ={"Content-Type" : "application/json", "Accept" : "application/json"}
self.new_paper = {"title": "ABC"}
self.new_paper2 = {"title": "DEF"}
def test_get_on_root_returns_html_hello_world(self):
resp = requests.get(self.base_url)
self.assertEqual(resp.content, "<html><body>Hello, new world</body></html>")
def test_get_on_paper_returns_id_in_html(self):
for id in 1,2,3:
resp = requests.get(self.paper_url + str(id))
self.assertEqual(resp.status_code, 200)
self.assertEqual(resp.content, "<html><body>" + str(id) + "</body></html>")
def test_get_on_paper_returns_id_in_json(self):
for id in 1,2,3:
resp =requests.get(self.paper_url + str(id), \
headers=self.json_headers)
self.assertEqual(resp.status_code, 200)
self.assertEqual(resp.content, '{"id":' + '"' + str(id) + '",'\
'"title":'+ '"' + str(id) + '"}')
def test_put_new_paper(self):
url = self.paper_url + '0'
# delete it first if present
r = requests.delete(url)
resp = requests.put(url, data=self.new_paper, headers=self.json_headers)
self.assertEqual(resp.status_code, 201)
self.assertEqual(resp.content, '{"id":"0","title":"ABC"}')
# Test durability
resp2 = requests.get(url)
def test_put_updates_paper(self):
url = self.paper_url + '0'
resp = requests.get(url)
# Paper exists
self.assertEqual(resp.status_code, 200)
resp2 = requests.put(url, data=self.new_paper2, headers=self.json_headers)
self.assertEqual(resp2.status_code, 200)
self.assertEqual(resp2.content, '{"id":"0","title":"DEF"}')
requests.delete(url)
def test_delete_paper(self):
# create it first
url = self.paper_url + '0'
resp = requests.put(url, data=self.new_paper, headers=self.json_headers)
self.assertEqual(resp.status_code, 201)
resp1 = requests.delete(url)
self.assertEqual(resp1.status_code, 204)
# test if durable
resp2 = requests.get(url)
self.assertEqual(resp2.status_code, 404)
def test_post_new_paper(self):
resp = requests.post(self.paper_url, data=self.new_paper,
headers=self.json_headers)
self.assertEqual(resp.status_code, 201)
self.assertNotEqual(resp.content, '')
def test_post_specific_paper_creates_another(self):
url = self.paper_url + '1'
resp = requests.post(url, data=self.new_paper, headers=self.json_headers)
self.assertEqual(resp.status_code, 201)
self.assertEqual(resp.content, '{"id":"1","title":"ABC"}')
# new one was created
self.assertNotEqual(resp.headers["location"], None)
# the new one is not the one which the POSt was apllied to
self.assertNotEqual(resp.headers["location"], self.paper_url+'1')
def test_put_without_data_is_malformed(self):
url = self.paper_url + '1'
resp = requests.put(url, data = {}, headers=self.json_headers)
self.assertEqual(resp.status_code, 400)
if __name__ == "__main__":
suite = unittest.TestLoader(verbosity=2).loadTestsFromTestCase(TestPaperAPI)
unittest.TextTestRunner.run(suite)
priv/dispatch.conf
{["paper", id], prp_paper, []}.
{["paper"], prp_paper, []}.
{["dev", "wmtrace", '*'], wmtrace_resource, [{trace_dir, "traces"}]}.
% The canonical resource for everything else
{[], prp_resource, []}.
src/prp_paper.erl
-module(prp_paper).
-export([init/1, content_types_provided/2, content_types_accepted/2,
allowed_methods/2, resource_exists/2, to_html/2, to_json/2,
from_json/2, delete_resource/2, post_is_create/2, create_path/2,
allow_missing_post/2]).
-include_lib("webmachine/include/webmachine.hrl").
init(Config) ->
prp_schema:init_tables(),
prp_schema:fill_with_dummies(),
{{trace, "traces"}, Config}. %% debugging
content_types_provided(RD, Ctx) ->
{[ {"text/html", to_html}, {"application/json", to_json} ], RD, Ctx}.
content_types_accepted(RD, Ctx) ->
{ [ {"application/json", from_json} ], RD, Ctx }.
allowed_methods(RD, Ctx) ->
{['GET', 'POST', 'PUT', 'DELETE', 'HEAD'], RD, Ctx}.
resource_exists(RD, Ctx) ->
Id = wrq:path_info(id, RD),
{prp_schema:paper_exists(Id), RD, Ctx}.
to_html(RD, Ctx) ->
Id = wrq:path_info(id, RD),
Resp = "<html><body>" ++ Id ++ "</body></html>",
{Resp, RD, Ctx}.
to_json(RD, Ctx) ->
Id = wrq:path_info(id, RD),
{paper, Id1, Title} = prp_schema:read_paper(Id),
Resp = paper2json(Id1, Title),
{Resp, RD, Ctx}.
from_json(RD, Ctx) ->
from_json(RD, Ctx, get_title(RD)).
spec from_json(wm_reqdata(), any(), {error, no_data})
-> {{halt, 400}, wm_reqdata(), any()};
(wm_reqdata(), any(), string())
-> {boolean(), wm_reqdata(), any()}.
from_json(RD, Ctx, {error, no_data}) ->
%% There is nothing to post, it's malfomed
{{halt, 400}, RD, Ctx};
from_json(RD, Ctx, Title) ->
Id = id_from_path(RD),
Resp = set_location_header_if_not_exists(RD, Ctx, Id),
prp_schema:create_paper(list_to_integer(Id), Title),
Resp1 = wrq:set_resp_body(paper2json(Id, Title), Resp),
{true, Resp1, Ctx}.
delete_resource(RD, Ctx) ->
Id = wrq:path_info(id, RD),
prp_schema:delete_paper(Id),
{true, RD, Ctx}.
%%%%%%%%%
% POST
%%%%%%%%%
post_is_create(RD, Ctx) ->
{true, RD, Ctx}.
allow_missing_post(RD, Ctx) ->
{true, RD, Ctx}.
create_path(RD, Ctx) ->
Path = "/paper/" ++ integer_to_list(generate_id()),
{Path, RD, Ctx}.
%%%%%%%%%%%%%%%%%%%%%%%%%%
% Private Helpers
%%%%%%%%%%%%%%%%%%%%%%%%%%
-spec get_title(wm_reqdata()) -> string() | {atom(), atom()}.
get_title(RD) ->
case wrq:req_body(RD) of
<<"title=", Title/binary>> ->
binary_to_list(Title);
_Else ->
{error, no_data}
end.
-spec id_from_path(wm_reqdata()) -> string().
id_from_path(RD) ->
case wrq:path_info(id, RD) of
undefined->
["paper", Id] = string:tokens(wrq:disp_path(RD), "/"),
Id;
Id -> Id
end.
-spec set_location_header_if_not_exists(wm_reqdata(), any(), string()) -> wm_reqdata().
set_location_header_if_not_exists(RD, Ctx, Id) ->
case resource_exists(RD, Ctx) of
{false, _, _} ->
wrq:set_resp_header("Location", Id, RD);
{true, _, _} -> RD
end.
-spec paper2json(integer(), string()) -> string();
(string(), string()) -> string().
paper2json(Id, Title) when is_integer(Id) ->
paper2json(integer_to_list(Id), Title);
paper2json(Id, Title) ->
mochijson:encode({struct, [
{id, Id},
{title, Title} ]}).
-spec generate_id()->integer().
generate_id() ->
mnesia:table_info(paper, size) + 1.
Ports to other Platforms
[edit | edit source]Webmachine originally is written in Erlang and can only be used from Erlang code. For using its priniciples it was ported to various other platforms.
| Language/Platform | Title |
| Ruby | webmachine-ruby[12], |
| Python | dj-webmachine [13], |
| Agda | Lemmachine[14] |
| JVM Languages, especially Java, Scala, Clojure and JRuby (via Clojure) | Clothesline[15] |
| Clojure | Bishop[16] |
Porting a Webmachine Application to Cowboy
[edit | edit source]In late 2011[17] the new HTTP server Cowboy[18] was publicly released and gained a lot of momentum in the Erlang community because of its performance and its clean, small and modular codebase. The Cowboy authors reimplemented Webmachine's HTTP handling which makes it possible to easily port a Webmachine application to Cowboy.
The only thing to be changed is the handling of strings. Since Cowboy strictly uses binary strings (hence no list of chars) some type conversions are no longer necessary and string processing is sped up[19]. In addition it may provide a generally even better performance as seen in a benchmark[20].
Comparison to similar Technologies
[edit | edit source]Sinatra and Webmachine
[edit | edit source]Sinatra can be considered a framework which addresses a similar class of problems – building a REST API. Since it is implemented in Ruby its interface and programming model is much different because it is essentially a domain-specific language. But both frameworks have in common that they are small and generic which gives a lot of flexibility and performance compared to full-stack frameworks. They should be used when there are specific needs and no scaffolding or MVC architecture is desired.
A main difference between Sinatra and Webmachine is the rich ecosystem of libraries and examples from the Ruby community while the Erlang world lacks a lot of reusable open source libraries e.g. for image processing, common cloud provider API and so forth[21].
Leveraging the Erlang Platform
[edit | edit source]
Webmachine has some clear advantages for some use cases because of its Erlang implementation. As Erlang is intended for use in high performance, distributed and fault tolerant applications[22] [23], a Webmachine application benefits of the already done work by the Erlang VM and the Open Telecom Platform (OTP), a collection of middleware libraries and applications. As seen in the code example there is little error handling because of the Erlang philosophy of "let it crash": A seldom error should not be handled in the code because it decreases readability and increases its complexity – it should just produce an uncatched runtime error. This optimistic programming can suprisingly lead to fewer errors and downtimes because of the use of supervisors[24]. In Erlang, a supervisor is a process which starts, stops and monitors child processes. Child processes can be workers or other supervisors to build supervision trees. Processes[25] are threads of execution inside the Erlang Virtual Machine called BEAM with separated heaps which are scheduled from the SMP emulator within the runtime. This means since Erlang programs are modeled in processes which send each other asynchronous messages, the runtime automatically utilizes all physical processors or processor cores[26]. In addition the VM makes all I/O calls asynchronous and schedules other processes while waiting for the operating system[27].
In figure 3 is shown that a Webmachine application starts a supervisor (in this case prp_sup, which is defined in src/prp_sup.erl). The supervisor starts and monitors a process which interfaces between the Mochiweb server and Webmachine (mochiweb_webmachine) which starts and supervises all request acceptors. This means for each request an Erlang process is started which handles it and a crash is isolated in that process so it only affects one user and keeps the whole application running. But chances are high that the user with the crashing request doesn't notice the crash at all – the supervisor process, which traps that crash, captures the valuable state of the crashing process and restarts it with that information so nothing gets lost.
Conclusion
[edit | edit source]Webmachine is a great entry point to Erlang because it is a small and focused framework. Its aim to let users easily write a correctly behaving REST API is met. The graphical tracing to see how a request was handled in the framwework plus the user defined callbacks is a great way to debug and helps in many situations because it provides transparency to make the framework less magical. If Erlang might be not the best implementation choice a variety of Ports to other platforms are available.
It also is a mature framwork which is constantly tested due to the use in Riak and the backing from the company Basho.
However, there are some difficulties during development: The error messages are often only the erlang exception plus a complete print of the whole ReqData (the state passed in to every function) object which is clumsy, deeply nested, and mostly not helping at all. In addition it lacks of a variety of good examples and a sound documentation. Therefore it is often necessary to test the behaviour of the framework which makes a good testing toolchain essential (which holds true for every software project).
Another drawback is the inconsistency of types used in Webmachine and Mochiweb which makes type conversions often necessary. It would be great if Webmachine did type conversions to circumvent Mochiweb's non uniformity. It should provide bitstrings (String in a binary container via the bit syntax) which makes pattern matching in strings easier and string operations faster compared to the implementation of strings as lists of characters instead of a vector/array of characters which would allow access instead of . But this datatype issue can be avoided by using the Cowboy webserver instead of Mochiweb.


Notes
[edit | edit source]- ↑ "Mochiweb". Retrieved 2012-07-22.
- ↑ Sheehy, Justin (2011). "Webmachine: a Practical Executable Model of HTTP". InfoQ. Retrieved 2012-07-22.
- ↑ Reitz, Kenneth. "Requests: HTTP for Humans". Retrieved 2012-07-22.
- ↑ "EUnit". Ericsson. Retrieved 2012-07-22.
- ↑ 5.0 5.1 Müller, Willi. "Webmachine-Example". Retrieved 2012-07-22.
- ↑ "Comprehensive Erlang Archive Network". Retrieved 2012-07-22.
- ↑ "Download Erlang OTP". Erlang Solutions. Retrieved 2012-07-22.
- ↑ "Webmachine". Basho Technologies. Retrieved 2012-07-22.
- ↑ "Webmachine Dispatching". Retrieved 2012-07-22.
- ↑ "Status Code Definitions: 409 Conflict". W3C. Retrieved 2012-07-22.
- ↑ "Webmachine Diagram". Basho Technologies. Retrieved 2012-07-22.
- ↑ "Webmachine for Ruby". Retrieved 2012-07-22.
- ↑ "Dj-Webmachine". Retrieved 2012-07-22.
- ↑ "Lemmachine". Retrieved 2012-07-22.
- ↑ "Clothesline". Retrieved 2012-07-22.
- ↑ "Bishop". Retrieved 2012-07-22.
- ↑ Hoguin, Loïc (2011). "A Cowboy quest for a modern web" (PDF). Erlang Factory. Retrieved 2012-07-22.
- ↑ "Cowboy". Retrieved 2012-07-22.
- ↑ "How do I represent a text string?". Ericsson. Retrieved 2012-07-22.
- ↑ Ostinelli, Roberto (May 2011). "A comparison between Misultin, Mochiweb, Cowboy, NodeJS and Tornadoweb". Retrieved 2012-07-22.
- ↑ Dimandt, Dimitrii (2012). "Erlang Sucks". Erlang User Coference. Retrieved 2012-07-22.
- ↑ "1 million is so 2011". WhatsApp. Retrieved 2012-07-22.
- ↑ Negri, Paolo. "Erlang as a cloud citizen". Retrieved 2012-07-22.
- ↑ "Supervision Principles". Ericsson. Retrieved 2012-07-22.
- ↑ "Processes". Ericsson. Retrieved 2012-07-22.
- ↑ "The SMP emulator". Ericsson. Retrieved 2012-07-22.
- ↑ Logan, Martin; Merritt, Eric; Carlsson, Richard (2010). Erlang/OTP in Action. Manning Publications, Greenwich. p. 19. ISBN 9781933988788. http://www.manning.com/logan/.
Further Reading
[edit | edit source]Webmachine related documents online
[edit | edit source]- "Webmachine". Basho Technologies. Retrieved 2015-07-29.
- Sheehy, Justin (2011). "Webmachine a Practical Executable Model of HTTP". QCon. Retrieved 2015-07-29.
- "Webmachine mechanics". github. 2014-11-23. Retrieved 2015-07-29.
- "Webmachine resolution flowchart (HTTP/1.1 headers <-> response status)". github. 2014-11-23. Retrieved 2015-07-29.
{kind=link}
- Miles, Christopher (2012-05-07). "Bishop: Makes Your Web Service Shiny". Retrieved 2015-07-29. – A blogpost explaining Bishop
Erlang online resources
[edit | edit source]- "Learn you some Erlang". Retrieved 2015-07-29. – a good resource to learn Erlang
- "Erlang-bookmarks". Retrieved 2015-07-29.
Books on Erlang/OTP
[edit | edit source]- Logan, Martin; Merritt, Eric; Carlsson, Richard (2010). Erlang/OTP in Action. Manning Publications, Greenwich. ISBN 9781933988788. http://www.manning.com/logan/.
- Armstrong, Joe (2014-08-12). Programming Erlang (2nd edition) – Software for a Concurrent World. The Pragmatic Programmers, Raleigh, North Carolina. ISBN 978-1-93778-553-6. https://pragprog.com/book/jaerlang2/programming-erlang.