
Psycholinguistics/Acoustic Phonetics
Introduction
[edit | edit source]Acoustic phonetics is the study of the physical features of speech sounds, in particular those that are linguistically relevant and can be detected by the human ear, and the medium in which they travel. All sounds are produced by movement of molecules (typically of air); they move in a vibrating-like fashion, creating periods of rarefaction (farther apart) and compression (closer together) between molecules. T the air, they create many cycles that, as a whole, can be referred to as a wave. The speed of the vibrations (compression + rarefaction) is called the frequency and is a very common measure of sound. The unit of measurement for frequency is Hertz (Hz) and 1 Hz is equal to 1 cycle/second. Humans are typically able to detect sound waves with frequencies of 20-20,000 Hz traveling through air. Acoustic phonetics uses the frequencies of these sound waves to precisely analyze speech. By combining the knowledge of articulatory phonetics and with use of a spectrograph, researchers have been able to pin point exact values and acoustic characteristics and use them to define particular vowels and consonants. For this reason, acoustic phonetics is especially important when considering vowels, as they are more difficult to define within the realms of articulatory phonetics (See the chapter on Articulatory Phonetics for more information). The logistics of how this is done is extremely interesting and will be explained below, along with the unique characteristics of common, American English speech sounds. I will begin by physically describing speech sounds (jump to Speech Sounds), move on to explain the spectrograph and spectrogram (The Spectrograph), and finalize the chapter with information on how to read the spectrogram and use it to identify particular speech sounds (Reading a Spectrogram). It is valuable to note that the information below may not apply to all languages, as speech sounds and even the way of producing identical speech sounds can differ between languages.
Speech Sounds
[edit | edit source]Physically disrupting the placement of air molecules (or molecules of another medium that sound can travel in) produces sound, but acoustic phonetics is concerned only with speech sounds. To produce speech sounds, we push air from the lungs through the glottis which makes the vocal chords vibrate. These vibrations occur in a pulse-like manner, pushing air out of the mouth or nose and displacing air with each pulse. The variations in air pressure due to these pulses can be represented as a waveform, which is what acoustic phonetics uses to characterize speech sounds. While articulatory phonetics (see this Wiki page for more information) defines speech sounds using manner/place of articulation, acoustic phonetics looks at the properties of the sound waves produced and links them to articulatory characteristics (this will be better explained in the section “Reading a Spectrogram”; jump to it).
What is considered linguistically relevant?
[edit | edit source]There are many possible speech sounds that can be used in a language but not every sound is used in every language, and the same sounds can be used in different ways depending on the language or dialect. In the latter case, acoustic phonetic properties of a word can change from language to language, and even dialect to dialect. For example, the acoustic characteristics at the end of the word “checker” would differ in British English compared to American English. The speech sounds actually used in a particular language are considered relevant, while any others are not considered when studying acoustic phonetics of that language. An example of a sound not heard in English but used in other languages are clicks, such as the (post)alveolar click [!]. Press play below to hear what a click sounds like; in this example, [!] is being spoken with [a] in the sequence [ǃa: aǃa:].
There are also sounds that can be made by the vocal tract, like coughs and burps, that are not considered relevant speech sounds in any language. To sum up, the relevance of a speech sound depends on the language you are interested in, and as a general rule, acoustic phonetics looks at the speech sounds meaningfully produced within a language. Some of the major components of speech sounds are described below.
Characteristics of Speech Sounds
[edit | edit source]Speech sounds can be classed as either sonorants or obstruents. Sonorants include nasal stops, approximants and vowels, and have even, periodic waveforms that compress air molecules at regular, repeating intervals. Oral stops, affricates and fricatives are obstruents and display uneven, aperiodic waveforms.
To produce nasals, the velum is lowered and air flows through the nasal cavity (e.g. /m/ and /n/ in "man"). Approximants occur when there is more constriction in airflow through the vocal tract compared to vowels, but less constriction than with consonants (e.g. glides, like /y/ in "yo" or /w/ in "waffle"). Vowels are produced when articulators are completely separated and air flows freely, without constriction, through the vocal tract (/a/, /e/, /i/, /o/, and /u/ are all vowels in English and can make different sounds, depending on the environment in which they are found; e.g. /u/ in "tune" and /u/ in "sun" are pronounced differently).
Frequency
[edit | edit source]
The frequency of a wave refers to the number of times a waveform completes one full cycle within a second. It is measured in Hertz (Hz), which is equal to the number of cycles per second. The thumbnail to the right is an example of a sinusoidal wave. The wavelength represents one cycle. You can see that the cycle contains two crests: one peak (where the wave is furthest above the baseline, or has the highest amplitude above the baseline) and one trough (where the wave is furthest below the baseline, or has the lowest amplitude from baseline). The wave begins to repeat itself after both crests have occurred. The crests correspond with rarefaction and compression of the molecules within the medium through which the sound is traveling. This repetition occurs in all periodic waves, but not aperiodic waves.
Frequency is the more objective term for pitch, which can sometimes be quite subjective. The higher the frequency of a sound, the higher its pitch will be. The human ear can detect sound with frequencies between 20-20,000 Hz, but most speech sounds are within the range of 100-6000 Hz. To put this into perspective, an average male would speak with a lower pitch, therefore his frequency would be towards the lower end of that spectrum (approximately 120 Hz on average).
Calculating Frequency
[edit | edit source]It is not always easy to calculate the frequency of waves because not often is there a perfect ratio of one cycle/second. For this reason, there is a formula used to calculate frequencies:
frequency (Hz) = number of cycles / time (sec)
In the image above, assuming that the horizontal axis represents time in seconds, we see that 1 cycle occurs in about 6.25 seconds. Using the formula for frequency, we can determine that this wave has a frequency of 0.16 Hz.
frequency (Hz) = 1 (number of cycles) / 6.25 (time in seconds) = 0.16 Hz
This tells us that the pitch of this sound is extremely low. If you recall the range of perceptibility allowed by the human ear, this tone would not even be heard by humans.
Intensity
[edit | edit source]The intensity of a sound wave is measured in decibels (dB) and represents the power and loudness of the wave. Intensity is correlated with the amplitude of the wave, or how high above (compression) or below (rarefaction) the baseline the wave reaches in each cycle. In this case, amplitude is an objective measurement of loudness, which is a more subjective measure of sound. Humans can typically hear from 0 dB to 120 dB, at which point sound is painfully perceived. Loudness of sound can be affected by distance as well as the composition of the propagating medium - the more efficient the propagating medium, the louder the sound. For example, think about the difference in loudness between shouting in air versus shouting underwater. One practical use for this concept is sound proof rooms, which would be built using highly efficient materials to absorb as much noise as possible, decreasing both the loudness of a sound and it’s distance travelled.
Timbre
[edit | edit source]Timbre (also known as "tone") refers to the shape/pattern of the waveform. Each speech sound has a unique shape responsible for giving it a unique sound. That is, the timbre of a sound is what makes it possible for us to differentiate one sound from the next and combine different sounds to communicate different meanings using language.
However, most speech sound waves are not as simplistic as the examples used above in the frequency section. In fact, the above examples would be a waveform of a pure tone, which is computer-generated (artificial) and does not occur in any natural sound. Rather, speech sounds are composed of multiple sinusoidal waves (shown on top in the image below) that combine to create a more complex wave, characteristic to the specific sound (shown on bottom).

Although the bottom waveform looks quite complicated, it is often broken down into its various sinusoidal wave components (i.e. the top waves, which vary in frequency and amplitude) for analysis. This is typically done on a computer using Fourier Analysis (see http://en.wikipedia.org/wiki/Fourier_analysis for more information).
Each individual sinusoidal wave is called a harmonic. When looking at speech sounds, the focus is mainly on the first four harmonics. The intensity decreases from the first harmonic up so that the lowest harmonic is the loudest, and as you move to a higher harmonic they get quieter. The frequency increases by multiples of the first harmonic, otherwise known as the fundamental frequency (Fo). The frequency of the sound wave as a whole is equal to the fundamental frequency, or the frequency of the lowest (1st) harmonic.
The complex shape of the waveform is due to the shape of the vocal tract when producing sounds, which reinforces some frequencies more than others. Since we make different shapes with the vocal tract to produce specific sounds, it makes sense for the waveform to change as the vocal tract changes to create each unique sound.
Quality
[edit | edit source]The quality of sound allows us to differentiate one musical instrument from another, or likewise one voice from another when dealing with speech. The quality of a sound depends on the shape and material of the propagating and closing media. Using music as an example, a trumpet (brass instrument) sounds different when compared to a clarinet (wooden instrument), or the vocal tract (as used by singers); But the trombone (another brass instrument) has a similar sound. Thus, the material of the apparatus can create a distinct sound class that can be further divided by shape. Different shapes lead to different harmonics. We learned that the fundamental frequency underlies the harmonics of a sound and provides the basic frequency of a sound. Thus, different harmonics, caused by different apparatus shapes, create different sounds. These changes are are considered to be changes in quality.
Learning Exercise 1
[edit | edit source]
In the above graph, the x-axis values represent time in seconds and the y-axis values represent loudness (amplitude) in decibels (dB).
Questions
1. What is the frequency of this wave?
2. What is the amplitude/intensity (in dB) of this wave?
3. With such pitch and loudness, would humans be able to hear this sound?
Click here for answers.
The Spectrograph
[edit | edit source]A spectrograph is a device used to measure and analyze the energy of waves. Spectrographs have been used in acoustic phonetics since the 1950’s and have been extremely useful in breaking down and analyzing phonetic segments of speech[1]. The energy input (the wave) is converted into a spectrogram, which is the output of a spectrograph.
Spectrogram
[edit | edit source]The spectrogram is a photo displaying properties of time, frequency and intensity of the speech sound. Below is an example of a spectrogram that displays the word “buy.”

The time is represented on the x-axis (horizontally) while the frequency is indicated using the y-axis (vertically), and the darkness of the band indicates intensity; that is, darker bands are more intense (thinking back to intensity as described for waveforms, this would tell us that the wave of the speech sound has a higher amplitude). With such information we can determine the duration of sounds, link them to specific phonemes and understand transitions (i.e. going from one phoneme to another) and patterns within speech segments.
There are two types of spectrograms that emphasize different components of sound. The narrow-band spectrograms make the pitch and harmonics easily visible, while wide-band spectrograms, as is the exemplified spectrogram for "buy," seem to highlight the formants and time which makes it easy to identify the cycle of a wave.
Formants
[edit | edit source]The dark, horizontal bands shown on a spectrogram are called formants. Formants represent speech sounds in characteristic ways, emphasizing certain frequencies with higher amplitudes. These frequencies represent the harmonics of the speech sound. The vocal chords vibrate more easily and intensely at the values of the formants or harmonics of a sound.
Each speech sound has a unique pattern or combination of the first three formants (called F1, F2 and F3, respectively) found on a spectrogram above the fundamental frequency (F0). These patterns occur consistently, no matter who the speaker, but the frequencies at which they occur often differ as they depend on the fundamental frequency of the speaker.* The fourth harmonic (F4) is also considered at times and represents the quality of the speaker’s voice. Therefore, F4 is completely variable and dependent on the speaker unlike the patterns of F1, F2 and F3. Formants above F4 are usually very faint, if visible at all, and as far as acoustic phonetics is concerned they do not necessarily give us any important, additional information about a sound. Conclusively, the shape of the wave, which represents timbre, is reflected in the values of the formant frequencies on a spectrogram, with emphasis on F1, F2 and F3.
- Remember, the fundamental frequency (F0) is the lowest frequency of a complex sound and is equal to the pitch of one’s voice. One’s individual F0 remains constant, but F0’s often vary between speakers. The harmonics (represented by the formants) can occur only at frequencies that are multiples of F0. Using a hypothetical example, a speech sound may show a pattern of F1 occurring at the 4th harmonic, F2 occurring at the 6th harmonic and F3 occurring at the 11th harmonic. The pattern of the harmonics will remain consistent as long as that specific sound is being produced, but the frequency of the harmonics may change with each speaker, representing the different pitches of different voices. So if one’s fundamental frequency is 100 Hz, we can determine the frequency of each formant by multiplying the associated harmonic by F0. Thus, formants associated with this sound will appear at 400 Hz for F1 (F1 occurs at the 4th harmonic, therefore F0 (100 Hz) x 4 = 400 Hz), 600 Hz for F2 (F2 occurs at the 6th harmonic, so F0 x 6 = 600 Hz) and F3 will appear at 1100 Hz (11th harmonic, 11 x F0 = 1100 Hz) on the spectrogram. The formula for this is:
| F0 = | freq. of # harmonic |
|---|---|
| # harmonic |
• where # represents the particular harmonic you’re interested in.
In the example stated above, we re-arranged the formula to find the frequency of the particular harmonic so that it was:
freq. of # harmonic = F0 x # harmonic; i.e., freq. of 3rd harmonic = 100 Hz x 3 = 300 Hz
F1 & F2
[edit | edit source]The first and second formants are particularly important when it comes to vowels. Contrary to most consonants, producing a vowel sound does not require contact between articulators, thus they are difficult to define and describe within articulatory phonetics. Using formant patterns, acoustic phonetics makes it possible to define specific vowels and differentiate them from one another. F1 predominantly describes the height of the tongue when the vowel is being produced and F2 reflects the place of the tongue and rounding of the lips when producing a vowel.
_(cropped)_(only_vowels).svg)
The basic rule is that high frequency F1 values are inversely related to the height of the vowel when being produced. This means that high vowels like [i] (sounds like the “ee” in beet) have low F1 values, and low vowels like [a] (sound like the “o” in cot) have high F1 values. Furthermore, F1 and F2 will be further apart for front vowels, like [i], and closer together for back vowels, like [a]. Below is a chart listing vowel sounds of American English and their places of articulation.
| Front | Central | Back | |
|---|---|---|---|
| High | i, I | ɨ | ʊ, u |
| Mid | e, ɛ | ə | ɔ, o |
| Low | æ | a | ɑ |
Chart reproduced from http://home.cc.umanitoba.ca/~krussll/138/sec5/ipavsna.htm
Note: High vowels are sometimes called “close” vowels, and low vowels are sometimes referred to as “open.” These pairs are essentially synonymic in this situation. The International Phonetic Alphabet (IPA) uses the terms open/close and describes vowels more precisely. There is an exhaustive Wikipedia page that lists and describes all sounds and charts: http://en.wikipedia.org/wiki/International_Phonetic_Alphabet . Please note that not all of these sounds are observed in American English.
Reading a Spectrogram
[edit | edit source]This section describes how some sounds pertinent to American English are transcribed on a spectrogram.
Sonorants
[edit | edit source]Sonorants are a sound class including vowels, nasals (e.g. [m] and [n]) and approximants (e.g. glides like [j], which sounds like "y" in yo-yo, or laterals like [l] or [r] in "later") and are produced without constricting airflow in the vocal tract.

Monophthongs
[edit | edit source]Monophthongs are vowel sounds produced with a still tongue. They are single vowels that produce flat formants sometimes termed “steady states.” However, monophthongs do not always appear perfectly on a spectrogram, as they are often affected by surrounding consonant sounds. The vowels in the section “ F1 & F2” describe monophthongs.
Diphthongs
[edit | edit source]Diphthongs are functionally single sounds, but when being produced the tongue changes position moving from the position of one vowel sound to another. They are often referred to as “gliding vowels” since they smoothly transition from one formant to the other and are frequently made up of a vowel/glide combination. This is shown on a spectrogram as a change in F1 frequency corresponding to the individual monophthongs; going from a low vowel to a high vowel would cause F1 to lower. Likewise, if the production of the vowel sound requires movement toward the front of the mouth, F2 will rise and move further away from F1. Sometimes the positions of the lips are also altered when producing diphthongs. Moving the lips from a rounded position to an unrounded position causes F2 to increase in frequency, and it will decrease if the lips transition oppositely.
-
 Spectrogram of the word "buy." Click the image to enlarge.
Spectrogram of the word "buy." Click the image to enlarge.
Nasalization
[edit | edit source]
It is important to realize that there is a difference between nasalized vowels and nasal vowels. A nasalized vowel is surrounded and affected by a nasal stop. For example, the vowel often sounds nasal when pronounced in the word “man,” because both [m] and [n] are nasal stops. In this instance, a monophthong is being influenced by the surrounding consonants and we would be able to see this from a spectrogram.
Nasal vowels are always produced nasally, regardless of surrounding sounds (i.e. air flows through the nasal cavity to produce the sound), but they are not typically produced in English; French is an example of a language containing nasal vowels (e.g. in the word meaning “end” – fin). Nasal vowels resemble some oral vowels but, on a spectrogram, contain a “nasal” formant at approximately 250 Hz and two other significant formants located above the “nasal” formant. The higher formants are still characteristic of the particular nasal vowel, but the nasal formant below remains at 250 Hz for any nasal vowel.
Rhoticised Vowels
[edit | edit source]The term “r-coloring” gives reference to rhoticised vowels. Rhoticised vowels exist when [r] influences a surrounding vowel. However, there are language that can have rhotic vowels without the influence of [r] (similar to nasal vowels in nasalization). Both types of rhoticisation occur in English. On a spectrogram, F3 lowers when rhoticisation is present.
-
 This is a spectrogram of the word "red." Click the image to enlarge.
This is a spectrogram of the word "red." Click the image to enlarge. -
 This is a spectrogram of the word "bed." Click the image to enlarge.
This is a spectrogram of the word "bed." Click the image to enlarge.


Although "bed" and "red" are very similar words, you can see that their spectrograms appear to be quite different. The vowel in "red" is rhoticized by the initial [ɹ] and we can clearly see that F3 is lowered, especially when comparing it to the "bed" spectrogram.
Other Sonorants
[edit | edit source]Approximants and nasals make up the consonant sonorants and have more specific characteristics on a spectrogram than vowels. Examples are listed below:
• Laterals (class of approximant; e.g. [l] like the "l" in lady): have additional formants at 250 Hz, 1200 Hz and 2400 Hz.
• Nasals (e.g. [m] and [n] in "man): have additional formants at 250 Hz, 2500 Hz and 3250 Hz.
• Rhotics (class of approximant): e.g. [ɹ] occurs post-vocalically, normally at the end of English words (e.g. "r" in summer), and is shown on a spectrogram as a lowered F3 and F4.
Obstruents
[edit | edit source]Obstruents are consonant sounds produced when the vocal tract is constricted and airflow is therefore obstructed in some way. Stops, affricates and fricatives make up the obstruent class of sounds, and each produce unique characteristics on a spectrogram.
Stops
[edit | edit source]Sometimes the formant patterns appear non-existent at points on a spectrogram. This lack of activity indicates the production of a stop. If the stop is voiced, it will be shown by a series of marks along the bottom of the spectrogram. These marks are called a “voice bar” and do not occur in voiceless stops.
Because there is nothing shown on the spectrogram in the presence of a stop, we cannot infer place of articulation based on the spectrogram. Phoneticians rely on surrounding sound information and transitional information, like whether there are aspiration or frication marks, to figure out which stop may be occurring.
Click here to see the spectrograms of "bed" and "red," which both contain the voiced stop [d]. You can see the voice bar and an absence of activity above it, as well as aspiration completing the stop.
Fricatives
[edit | edit source]Fricatives are the most extremely aperiodic type of sound shown on a spectrogram. They appear as irregular, vertical striations within the higher frequencies. The resonant frequencies seem to be inversely related to the size of the oral cavity (how far forward obstruction takes place) so that frequency increases as the size of the oral cavity decreases. For example:
• [h] constricts the airway toward the back of the throat, so that the oral cavity is fairly large; it’s frequency is typically 1000 Hz
• [f] is a labiodental fricative that constricts the airway using the teeth and lip toward the front of the mouth; it’s frequency is higher at about 7000 Hz
So, the further back constriction exists, the higher the frequency of the noisy striations from fricative on a spectrogram.
Below is a spectrogram of the word "sing." There is silence before the onset of the word, where you can identify the noisy, high frequency "s" sound.
-
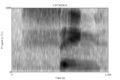 "Sing" spectrogram. Click to enlarge.
"Sing" spectrogram. Click to enlarge.

More information on sonorants and obstruents can be found by clicking on these links to the sonorants and/or obstruents sections in the Articulatory Phonetics chapter.
Transitions
[edit | edit source]Transitions occur when you move from a vowel or sonorant to the next consonant (recall that moving from one vowel sound to another is a diphthong). Transitions are used to identify specific stops and can reinforce what we know about fricatives. For example, transitioning from an alveolar or labial consonant to a vowel causes F2 to rise before front vowels but lower before back vowels. If the vowel precedes the consonant, the pattern is reversed so that F2 falls into the consonant coming from a high, front vowel and will rise coming from a back vowel.
By identifying vowels, which have standard formant patterns, we can “work backward” and infer the place of articulation of the preceding consonant, as the initial section of the second formant of a vowel can vary slightly depending on the preceding consonant. So, in the word “bee,” we have a labial consonant [b] followed by a frontal vowel [i]. We can easily identify the [i] vowel based on it’s unique formant pattern and the rising of F2 with the transition into the vowel tells us that the preceding consonant could be alveolar or labial. Additionally, you can notice the voice bar at the beginning due to the voiced stop [b] and aspiration before the beginning of the vowel sound.
-
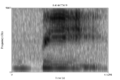 Spectrogram of the word "bee." Click image to enlarge.
Spectrogram of the word "bee." Click image to enlarge.

Transitions are described based on a locus. A locus is a reference point at which the transition seems to originate. In the example above, the locus could be used to help determine whether the preceding consonant is alveolar or labial. Loci are specific to placement of articulation and are located in the middle of the frequency range for a particular placement. Take alveolars, for example: the highest F2 frequency occurs in transition to a front vowel, and the lowest in transition to a back vowel. The locus of alveolars is located halfway between these points, in the middle of the frequency range, which is approximately 1800 Hz. Bilabials have a F2 locus at about 800 Hz, and velars have a locus of 3000 Hz for front vowels and 1200 Hz for back vowels. With two, high F2 loci, velars consistently fall when transitioning to vowels.
Voice Onset Time
[edit | edit source]Voice onset time (VOT) is also of use when trying to identify specific speech sounds. In particular, VOT highlights differences in aspiration of stops on a spectrogram. If stops are released before voicing begins (VOT), we will see a puff of air that signifies aspiration. In a voiceless stop, the aspiration is represented as aperiodic waves in high frequencies and the voicelessness continues after the stop is released.

VOT differences for English words "die," (top) which begins with a voiced stop, and "tie," (bottom) which begins with a voiceless stop, are shown on the spectrograms above. The aspiration at the beginning of "tie" is longer and highlighted and we can infer that the stop is released before voicing occurs.
Learning Exercise 2
[edit | edit source]1. There are 4 spectrograms below. Try to identify which month of the year is being said in each using your knowledge of acoustic phonetic characteristics. To narrow things down a bit, I've given an either/or option for each spectrogram.
Hint: Look for stops and fricatives to help identify or eliminate possibilities. Recall formant patterns of vowels (i.e. high vowels typically show low F1, etc.), as well as patterns of rhoticization and nasalization to fill in other blanks. Good luck! :)
You can click on the photos to make them larger.
Spectrogram 1: Is it May or September? 
Spectrogram 2: Is it October or December? 
Spectrogram 3: Is it February or November? 
Spectrogram 4: Is it August or July? 
Click here to find the answers.
2. The spectrogram below is of the sentence "Don't stop believing." Can you section the sentence into it's individual words? Use your knowledge obtained from this chapter and the previous learning exercises to identify the beginning/end of each word.

Click here to find the answers.
These spectrograms were created using Praat. Download the program so you can make your own creations at http://www.fon.hum.uva.nl/praat/.
Bibliography
[edit | edit source]Davenport, M. & Hannahs, S. J. (2010). Introducing Phonetics and Phonology (3rd edition). London: Hodder Education.
Fromkin, V., Rodman, R., Hyams, N., & Hummel, K. (2006). An Introduction to Language (3rd Canadian edition). Toronto: Thomson Limited Canada.
Jay, T. (2003). The Psychology of Language. Upper Saddle River, New Jersey: Prentice Hall.
References
[edit | edit source]- ↑ Joos, M. (1948). Acoustic phonetics. Language, 24, 5-137.